
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- airflow
- Go
- Docker
- redshift
- 자료구조
- http
- 정리
- 종류
- S3
- PYTHON
- airflow.cfg
- 데이터 파이프라인
- 컴퓨터네트워크
- Django
- HADOOP
- TIL
- 컴퓨터 네트워크
- 데브코스
- TCP
- AWS
- 데이터 웨어하우스
- 운영체제
- linux
- sql
- 데이터엔지니어링
- 데이터 엔지니어링
- 파이썬
- dockerfile
- 데이터베이스
- 가상환경
Archives
- Today
- Total
홍카나의 공부방
[DE 데브코스] 05.23 TIL - Redshift, Serverless, ELT 예시 본문
Data Engineering/프로그래머스 데브코스
[DE 데브코스] 05.23 TIL - Redshift, Serverless, ELT 예시
홍문관카페나무 2023. 5. 24. 15:18AWS Redshift 특징
- OLAP 기술을 사용하므로, 응답속도가 빠르지 않기 때문에 Production DB로 사용이 불가능하다.
- 디스크에 데이터를 레코드 별로 저장하는 것이 아니라, 컬럼 별로 저장한다.
- 컬럼별 압축이 가능하며, 컬럼을 추가하거나 삭제하는 것이 아주 빠르다.
- 레코드가 들어있는 파일을 S3로 업로드 후, COPY 명령어로 Redshift로 일괄 복사하는 벌크 업데이트를 지원한다.
- 고정 비용 SQL 엔진이지만, 최근 가변 비용 옵션도 제공한다.
- RedShift 최적화는 비교적 복잡하다. 한 클러스터 안에 두 대 이상의 노드로 구성되면 분산 저장되어야 한다. SnowFlake나 Bigquery는 엔진이 알아서 최적화를 해주긴 하지만, redshift는 그렇지 않다.
- 다른 데이터 웨어하우스와 같이 Primary Key Uniqueness를 보장하지 않는다.
AWS Redshift 스케일링, 레코드 분배
- 용량이 부족해질 때마다 새로운 노드를 추가하는 방식으로 스케일링(Scale-Out)하는게 일반적이다.
- Scale-Up 방식은 노드의 사양을 더 좋은 것으로 업그레이드하는 방식이다. (ex: dc2.large -> dc2.8xlarge)
- Snowflake나 BigQuery는 가변 비용으로 사용한 리소스에 해당하는 비용을 지불하나, 보통 Redshift는 그렇지 않다.
- 두 대 이상의 노드로 구성되면, 한 테이블의 레코드를 분배하기 위하여 Distkey, Diststyle, Sortkey 3개의 키워드를 알아야한다.

- 1) Diststyle은 레코드 분배가 어떻게 이뤄지는지를 결정한다. all, even, key(default is "even") even의 경우 round robin 형태로 모든 노드에 분배하게 된다. key인 경우 컬럼 선택이 잘못되면, Skew가 발생하면서 효율성이 떨어진다.
- 2) Distkey는 레코드가 어떤 컬럼을 기준으로 배포되는지 나타낸다. ( diststyle이 key인 경우에 사용 )
- 3) Sortkey는 레코드가 한 노드내에서 어떤 컬럼을 기준으로 정렬되는지 나타낸다. (기준은 보통 타임스탬프 필드가 된다.)
CREATE TABLE my_table (
column1 INT,
column2 VARCHAR(32),
column3 TIMESTAMP,
column4 DECIMAL(18, 2)
) DISTSTYLE KEY DISTKEY(column1) SORTKEY(column3);
-- my_table의 레코드들은 column1의 값을 기준으로 분배되고,
-- 같은 노드안에서는 column3의 값을 기준으로 소팅이 된다.
AWS Redshift Serverless
- 가변 비용 버전의 Redshift다.

- 초기 생성 및 설정후, 퍼블릭 접근을 원하면 기능을 켜줘야 한다.
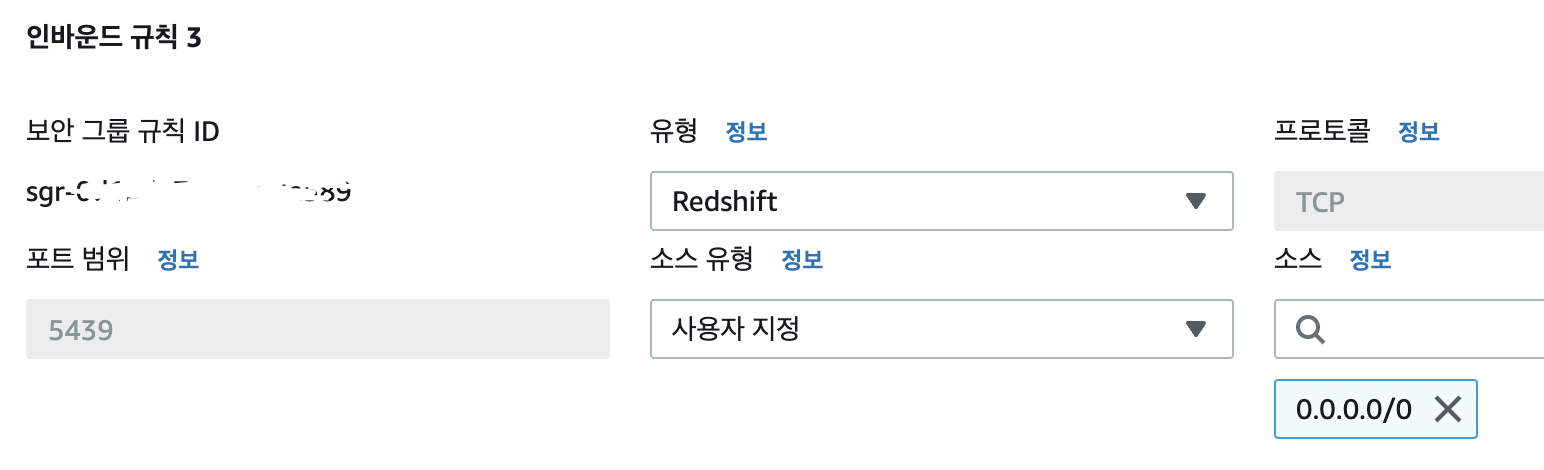
- 그리고 보안 그룹의 인바운드 규칙 설정도 올바르게 설정하였는지 다시 한 번 확인하자.
AWS Redshift 초기 설정

- 테이블을 만들기 전에, 스키마를 만들어서 카테고리에 맞게 테이블을 만들면 좋다.
- 위 그림의 예시로는 ETL의 결과로 raw data들이 저장된 raw_data 스키마, ELT로 데이터들이 JOIN 되거나 transform 되어 만들어진 테이블이 담긴 analytics 스키마, 테스트용 테이블이 담겨있는 adhoc 등으로 구성했다.
SELECT table_name
FROM information_schema.tables
WHERE table_schema = 'public';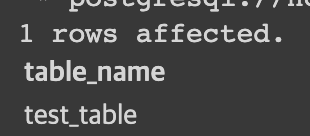
- 만약 스키마 없이 테이블을 만든다면, 그 테이블은 모두 public 스키마로 들어간다. ( postgreSQL 기준, MySQL은 'mysql'이라는 스키마에 들어감. )
- 스키마는 아래 코드처럼 만든다.
CREATE SCHEMA raw_data;
CREATE SCHEMA analytics;
CREATE SCHEMA adhoc;
CREATE SCHEMA pii;- 사용자(User) 생성은 다음과 같이 진행한다.
CREATE USER username PASSWORD '*****';- 스키마 별로 접근이 가능한 그룹을 만들고, 그룹에 사용자를 포함할 수도 있다.
CREATE GROUP analytics_authors;
ALTER GROUP analytics_authors ADD USER username;- 그룹의 문제는 계승이 안된다는 점이다. 즉, 너무 많은 그룹을 만들면 관리가 힘들어지는데, 이를 대체하기 위해 역할(Role)이 있다.
- 그룹의 생성은 CREATE GROUP, 그룹에 사용자 추가는 ALTER GROUP ~ ADD USER로 가능하다.
- 역할은 그룹과 달리 계승 구조를 만들 수 있다. 한 사용자는 다수의 역할에 소속 가능하다.
CREATE ROLE staff;
CREATE ROLE manager;
CREATE ROLE external;
GRANT ROLE staff TO ROLE manager; -- staff의 역할을 manager에게 부여
ELT 코드 예시
- 있는 정보로 새로운 정보를 만들어 내는 것이 ELT가 되는 것이다. 아래 코드처럼 CTAS 문법을 이용하여 만들 수 있다.
- raw_data 스키마에 있는 테이블을 조인해서 새롭게 analytics 스키마의 mau_summary 테이블을 만들었다.
CREATE TABLE analytics.mau_summary AS
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;
오늘 공부하며 어려웠던 내용
- S3 파일을 Redshfit로 COPY할 때 에러가 발생할 수 있는데, 이때는 아래 명령으로 확인할 수 있다.
SELECT * FROM stl_load_errors ORDER BY starttime DESC;
반응형
'Data Engineering > 프로그래머스 데브코스' 카테고리의 다른 글
| [DE 데브코스] 06.04 TIL - 트랜잭션과 Airflow 설치 (0) | 2023.06.04 |
|---|---|
| [DE 데브코스] 05.25 TIL - Redshift 심화, Fact/Dimension/외부테이블과 View 차이점 등 (0) | 2023.05.25 |
| [DE 데브코스] 05.22 TIL - 데이터 팀에 대하여, DevOps 등 (0) | 2023.05.22 |
| [DE 데브코스] 05.19 TIL - Lambda, Docker (0) | 2023.05.19 |
| [DE 데브코스] 05.18 TIL - CLI, DATABASE (0) | 2023.05.18 |
'Data Engineering/프로그래머스 데브코스' Related Articles
more


