
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 종류
- 정리
- 데이터베이스
- 데이터엔지니어링
- 운영체제
- 데이터 웨어하우스
- 데브코스
- linux
- Go
- HADOOP
- Docker
- AWS
- redshift
- 컴퓨터네트워크
- 가상환경
- airflow.cfg
- TCP
- S3
- 파이썬
- 데이터 파이프라인
- sql
- 컴퓨터 네트워크
- PYTHON
- 데이터 엔지니어링
- TIL
- http
- airflow
- Django
- 자료구조
- dockerfile
- Today
- Total
홍카나의 공부방
[Hadoop] HDFS 개요와 HDFS 접근 방법, MapReduce 본문
HDFS
HDFS(Hadoop File System)는 분산 처리에 사용하는 파일 시스템이다. HDFS는 데이터를 클러스터 전체에 걸쳐 분산시키고, 여러 컴퓨터에 걸쳐 저장한 데이터는 각 컴퓨터가 동시에 처리한다. 데이터는 블록 단위로 나누며, 블록은 기본 128MB를 가지게 된다.
모든 블록은 2개 이상의 복사본으로 저장이 된다. 단일 노드가 다운되더라도 블록을 잃어버리지 않기 위함이다.

노드의 종류
Node의 종류는 크게 다음 3가지 노드로 나눈다.
- Name Node(네임 노드)
- Client Node(클라이언트 노드)
- Data Node(데이터 노드)
네임 노드는 쉽게 말하면 관리자 노드로, 어떤 데이터가 어디에 저장되어 있는지를 관리한다. 도서관 관리자가 어떤 책이 어느 선반에 있는지 알고 있는 것처럼, 네임 노드는 파일의 메타데이터(이름, 권한, 위치 등)를 관리한다.
데이터 노드는 실제 데이터가 저장되는 곳이다. 도서관 방문자가 선반에서 책을 찾듯이, 클라이언트는 데이터 노드에서 필요한 데이터를 찾는다. 네임 노드가 어디에 어떤 데이터가 있는지 알려준다. 데이터 노드들은 네임 노드의 명령에 따라 데이터를 저장하고, 삭제할 수 있다. 여러 데이터 노드에 걸쳐서 데이터가 복사되어 저장된다.
클라이언트 노드는 실제로 데이터를 처리하려는 사용자나 어플리케이션이라고 볼 수 있다. 네임 노드에게 데이터의 위치를 질의할 수 있고, 해당 데이터 노드로부터 데이터를 읽거나 그 곳에 데이터를 쓰기도 한다.
HDFS 사용 방법
- UI
- CLI
- HTTP / HDFS 프록시
- Java Interface
- NFS Gateway
Ambari에서 HDFS에 접근하는 방법

하둡 클러스터 관리 도구인 Ambari를 이용하여 HDFS에 접근하고 살펴볼 수 있다. Ambari로 접속하여 오른쪽 상단 [Files View]를 누르면 폴더 형식으로 HDFS 상황을 살펴볼 수 있다.
리눅스 명령줄(Command Line Interface)로 접근하는 방법

VirtualBox 기반의 VM이나 docker 컨테이너로 구성된 HDFS에도 접근할 수 있다. 이 글에서는 docker 컨테이너로 올려놓은 HDP 내부에 접근해서 HDFS를 살펴본다. 먼저 docker 컨테이너 내부에 접근한다. 나같은 경우 maria_dev 계정으로 접근하기 위해서 -u 태그도 추가했다.
docker exec -it {-u username} {컨테이너 ID 또는 이름} bash
나는 `docker exec -it sandbox-hdp bash` 를 입력하였고, 컨테이너 내부로 들어온다. hadoop fs -ls / 를 입력하면 HDFS 루트 디렉토리에 있는 파일과 디렉토리 목록을 확인할 수 있고, hadoop fs -ls를 입력하면 현재 로그인한 계정의 최상단 디렉토리를 확인할 수 있다.
hadoop fs -ls /
hadoop fs를 입력하면 실행할 수 있는 명령어 리스트도 확인할 수 있다.
MapReduce
맵리듀스는 대용량 데이터를 분산 처리하기 위한 목적으로 개발된 프로그래밍 방법론이다. 맵리듀스 기술은 데이터를 분산 처리(Map)하고, 이를 다시 합치는(Reduce) 과정을 거친다.
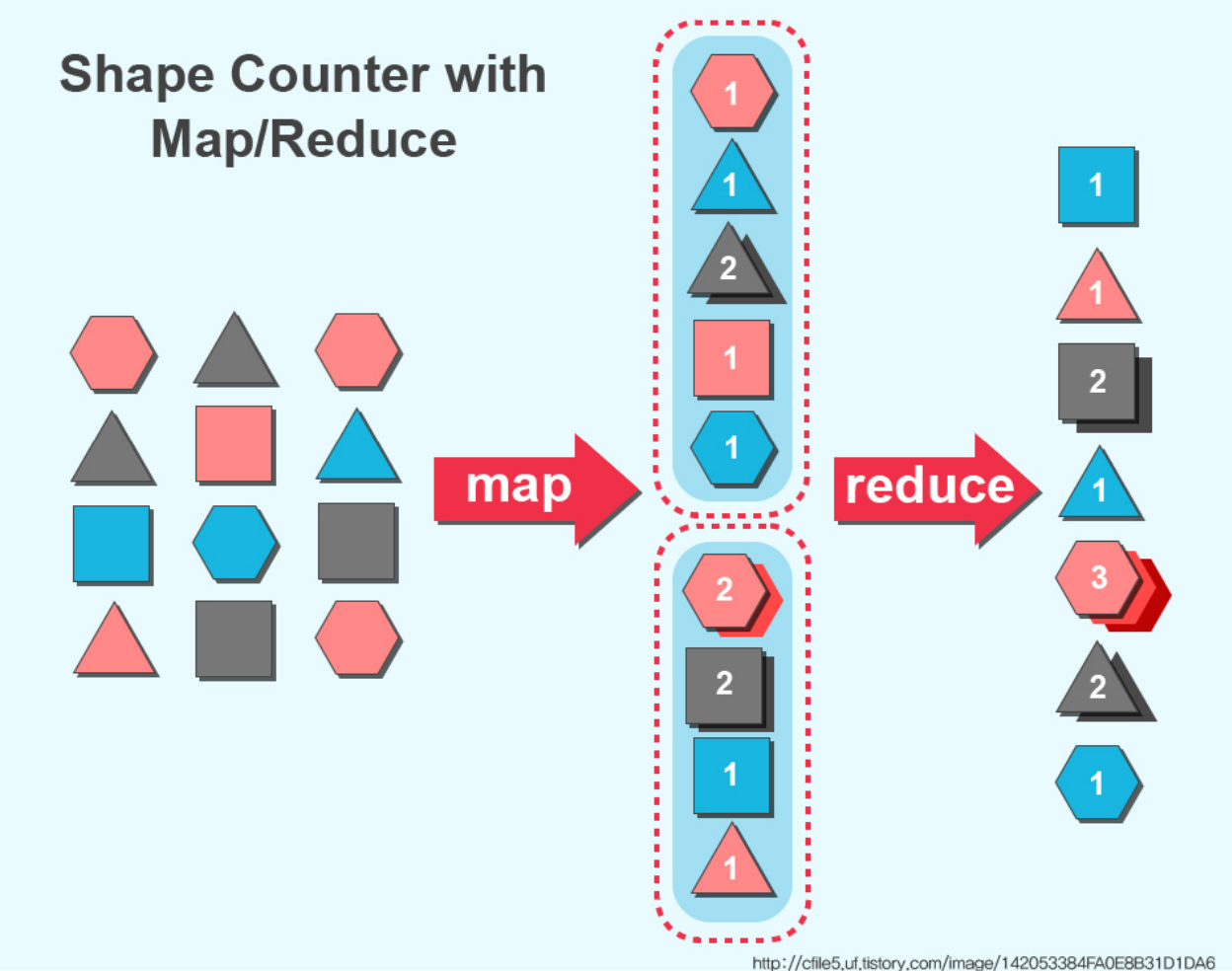
맵리듀스는 크게 Mapping - Shuffle and sort - Reducing의 과정을 거치는데, Mapping은 말 그대로 파이썬의 dictionary 자료구조처럼 key-value구조로 데이터를 정리하는 과정이다. 그리고 shuffling은 Map 작업과 Reduce 작업의 중간 과정인데, map 함수의 결과를 취합하고 reduce 함수로 데이터를 전달한다.
마지막으로 reduce함수를 거치면 모든 값을 합쳐서 사용자가 원하는 값을 도출할 수 있다. 현재 MapReduce는 Hive나 Spark와 같은 기술로 사용이 대체되고 있다.
'Data Engineering > Hadoop' 카테고리의 다른 글
| [Hadoop] MongoDB와 Hadoop (0) | 2024.05.27 |
|---|---|
| [Hadoop] Hive 소개와 작동 방식 (5) | 2024.05.26 |
| [Hadoop] Apache Spark 2.0 개요와 RDD, DataSet (0) | 2024.05.19 |
| [Hadoop] Apache Pig의 개요와 사용법 (0) | 2024.05.19 |
| [Hadoop] NCP에서 하둡 실습 환경 구축하기 (1) | 2024.05.11 |



