
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 파이썬
- S3
- http
- Go
- redshift
- 데브코스
- airflow.cfg
- AWS
- 자료구조
- 컴퓨터네트워크
- 데이터 웨어하우스
- sql
- 데이터 엔지니어링
- TIL
- PYTHON
- Django
- 데이터베이스
- HADOOP
- dockerfile
- TCP
- 정리
- Docker
- 데이터 파이프라인
- 가상환경
- 컴퓨터 네트워크
- linux
- 데이터엔지니어링
- airflow
- 종류
- 운영체제
- Today
- Total
홍카나의 공부방
[컴퓨터 네트워크] 7-1. IPv4 Datagram 구조, Fragment 본문
인터넷 프로토콜(IP)은 네트워크 계층에서 사용하는 전송 메커니즘이다.
IP에서 전송하는 패킷인 Ip Datagram을 살펴보자.
IP Datagram
ip datagram은 헤더와 데이터로 구성되어 있고, 헤더의 길이는 20-60bytes다.
데이터그램의 전체 길이는 20-65,535 bytes로 결정된다.

헤더에서 한 줄은 0부터 31비트까지 총 32비트(4바이트) 길이를 가지며,
표준 헤더는 5개의 줄을 가지니 총 20바이트의 길이가 될 것이다.
Options와 padding이 0부터 40바이트까지 추가적으로 붙을 수 있다.
위 그림에서 첫 번째 줄에 나오는 VER은 version이다.
version은 ipv4냐, ipv6이냐 여부를 알려주는 역할을 한다.
HLEN은 Header length이다.
Service type은 우선순위 및 DS(diffrerentiated service)로 나뉘는데,
우선순위는 특정 라우터에 있는 버퍼가 가득 찼을 때,
우선순위가 낮은 패킷을 버리고 우선순위가 높은 패킷을 먼저 처리할 수 있도록 만드는 것이다.
실시간 멀티미디어 패킷들이 우선순위가 낮아서 없어지는 대상으로 선정되기도 한다.
DS는 차등 서비스라고 번역이 되는데,
네트워크에 서비스 요청과 트래픽 특성(내가 어느정도 트래픽을 보낸다는 것을 알려주는)을 전달하는 서비스다.
이후, 네트워크가 가지고 있는 자원을 가지고 위 사항을 만족할 수 있는지 Admission Control을 보낸다.
전달 사항이 틀리지는 않는지 Traffic Monitoring도 진행한다. ( 대역폭의 특성을 만족시키는지 등등 )
Total length는 전체 길이다.
16bits니까 0에서 65,536의 길이를 가질 수 있을 것인데,
최소 길이는 헤더가 20바이트만큼 차지하니까 20이상은 될 것이다.
다음은 세번째 줄의 요소들을 살펴본다.
Time to live field는 Routing Loop 방지, Packet이 전파되는 범위를 제한하는 용도로 사용된다.
예를 들어 Packet의 무한 루프는 TTL 필드 값을 설정함으로써 예방할 수 있다.
Protocol field는 위에서 TCP가 보냈느냐 UDP가 보냈느냐 프로토콜을 확인할 수 있는 field다.
receiver입장에서는 Protocol field가 어떤 것이냐에 따라서 Demultiplexing을 하며 해당 프로토콜 값에 맞춰서 처리를 하게 된다.
protocol field 값들은 이미 IANA에 의해서 well-known 되어있다.

Header checksum은 checksum이 오류 탐지라는 뜻으로, 헤더의 오류 탐지를 담당한다.
Router에서 하는 일을 줄이기 위해 포함된다. 빠르게 체크하기 위해 Header만 탐지하게 된다.
라우터들이 패킷을 받으면서 VER를 보고, VER가 4면 Header checksum을 보고 오류가 있는지 없는지 확인하게 된다.
데이터에 대한 checksum은 TCP나 application이 하게 된다.
Fragment
Maximum Transfer Unit이 작으면 패킷이 fragment 되어야 할 필요가 있다.
파편화가 되면 패킷이 수신자에 도착한 이후 패킷들이 합쳐져야 하는데,
패킷을 합치기 위해서는 id, offset, flag(more fragment bit) 등의 여러 필드가 필요하다.
헤더는 원래의 헤더를 가져오게 된다. 데이터만 파편화 된다.
(Only Data in a datagram is fragmented.)

이 중에서 offset은 파편화된 패킷들의 시작과 끝 위치를 알려주기 위해서 필요하다.
파편화는 8의 배수로 자르게 된다. Fragmentation Offset이 13bits밖에 없기 때문이다.
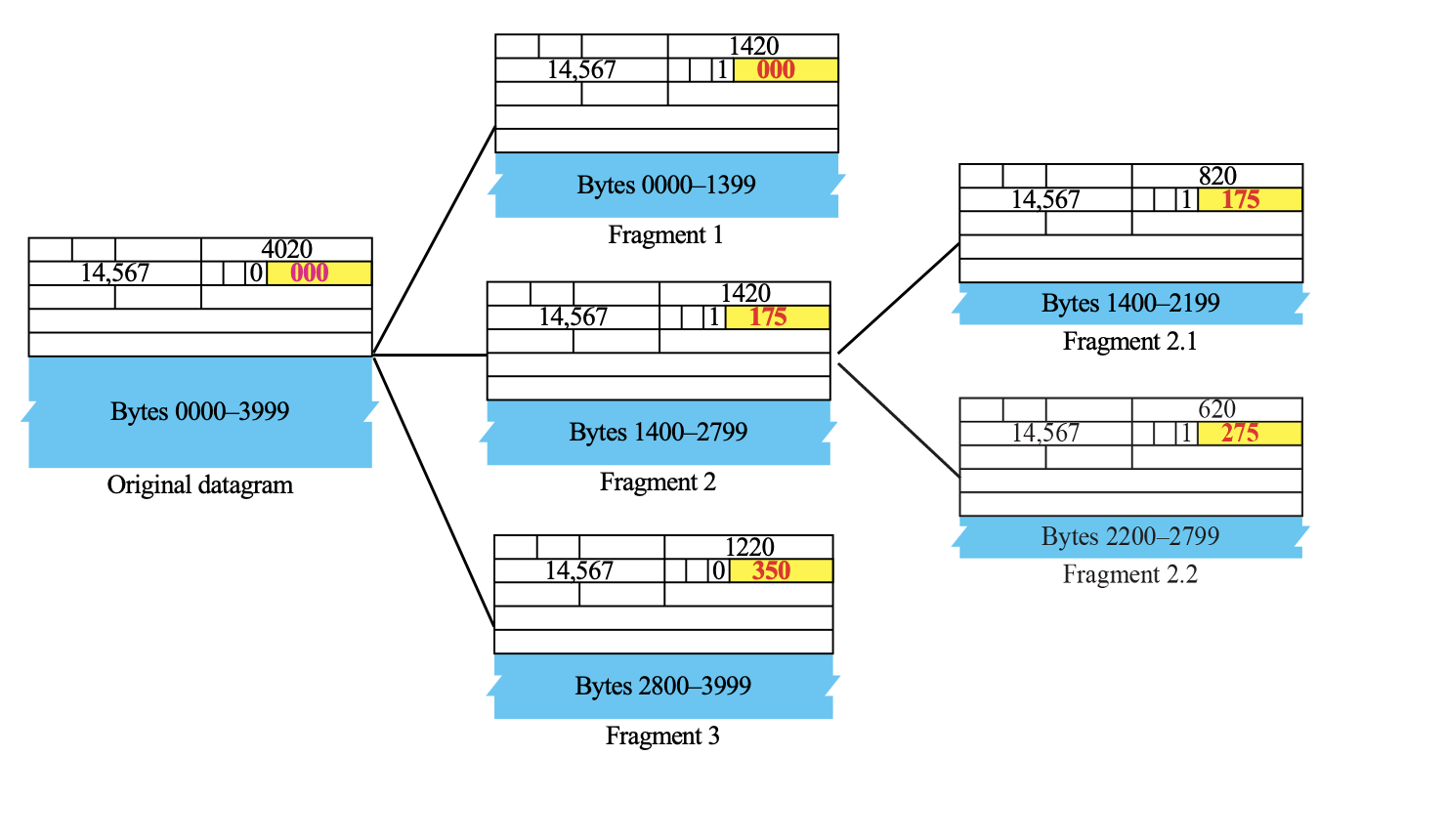
위에서 Offset 앞에 0,1이 포함된 것을 볼 수 있는데
이는 more fragment bit이고, 이게 0이면 뒤이어서 패킷이 들어오지 않는다는 뜻이다.
문제 예시)
- Offset value = 100, HLEN = 5, Total length = 100
첫 번째 바이트와 마지막 바이트의 Number는?
- 첫 번째 바이트 값은 해당 패킷의 오프셋 값이 100이니까 100x8 = 800bytes이고,
해더의 길이는 5 * 4bytes = 20bytes라는 것을 알 수 있다.
이 말은 해당 데이타그램에 80 bytes가 존재한다는 이야기다.
즉, 첫 번째 바이트 값은 800, 마지막 바이트 값은 879이다.
(바이트 값은 Total Length - Header의 길이를 빼고 Data 부분의 시작과 끝을 계산)
'Computer Network' 카테고리의 다른 글
| [컴퓨터 네트워크] 7-3. 네트워크 보안 서비스 종류 (0) | 2023.01.23 |
|---|---|
| [컴퓨터 네트워크] 7-2. 네트워크 공격 종류 (0) | 2023.01.23 |
| [컴퓨터 네트워크] 6-2. Python의 psutil을 이용하여 열린 포트 찾기 (0) | 2023.01.11 |
| [컴퓨터 네트워크] 6-1. 파이썬 포트 스캐닝(Port Scanning) 구현 (0) | 2023.01.11 |
| [컴퓨터 네트워크] 5-4. 사설망과 스머프 공격 (0) | 2023.01.11 |
