
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Django
- 정리
- sql
- HADOOP
- 데이터 파이프라인
- 데브코스
- dockerfile
- 컴퓨터네트워크
- 데이터베이스
- 파이썬
- PYTHON
- 종류
- redshift
- Docker
- linux
- 컴퓨터 네트워크
- TIL
- 자료구조
- 가상환경
- 운영체제
- S3
- TCP
- airflow
- 데이터 웨어하우스
- 데이터 엔지니어링
- 데이터엔지니어링
- AWS
- http
- airflow.cfg
- Go
- Today
- Total
홍카나의 공부방
[컴퓨터 네트워크] 12. Transport Layer(전송계층)과 포트 번호 vs Process ID, Pushing과 Pulling, UDP 왜써요? 본문
[컴퓨터 네트워크] 12. Transport Layer(전송계층)과 포트 번호 vs Process ID, Pushing과 Pulling, UDP 왜써요?
홍문관카페나무 2023. 4. 20. 22:26이번 글에서는 전송 계층에 대해 전체적으로 알아본다.
Process to Process, Layer 4
L3가 Host to Host 통신에 초점을 맞췄다면 L4에서는 Process to Process 간 통신에 초점을 맞춘다.
그리고 전송 계층의 TCP에서는 흐름제어, 오류제어, 혼잡제어라는 신뢰성 서비스를 제공한다.
전송 계층에는 UDP도 존재하는데 이는 비연결서비스로 구분되고, 이에 반해 TCP는 연결지향서비스로 구분된다.
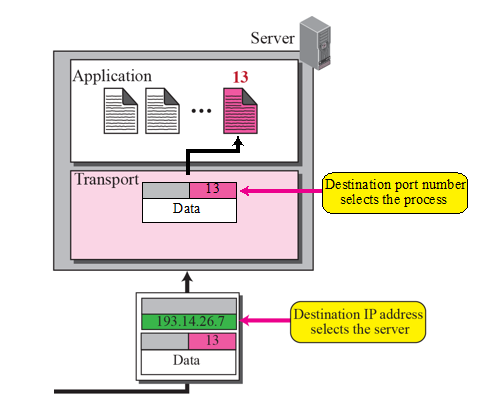
Port 번호 vs Process 번호
Port 번호라는 개념은 많이 들어봤을 것이다. 포트 번호는 네트워크에서 사용되는 '창구'라고 보면 된다.
하지만 우리가 작업관리자를 보면 Process ID라고 하는, 프로세스 번호가 있는데 왜 굳이 Port 번호를 이용하는 것일까?
(1) Process ID는 OS마다 다를 수 있기 때문이다. Process ID는 OS 공통 표준이 없다.
(2) Process ID는 외부 통신을 요청하는 host가 상대방의 PID를 정확히 알 수가 없다.
(3) Process ID는 운영체제에서 실행중인 프로세스에 할당한 것이다. 포트번호랑은 개념이 다르다.
그래서 바깥에서 통신할 때 상대방의 Process ID가 보이는게 아니고, Port number가 보이는 것이다.
우리가 응용 프로세스를 실행시킬 때 외부와 통신할 수 있는 창구를 마련해줘야 할 때가 있다.
이럴 때, 특정 포트를 어떤 프로그램이나 서비스에 할당하는 것을 바인딩(binding)한다고 하며
어떤 프로그램이나 서비스가 포트를 점유하고 있는 상태를 포트 바인딩(Port Binding)이라고 한다.
단, 0~1023번은 well-known service들의 포트 번호로 이미 선점되어 있으므로
해당 번호로는 포트 바인딩을 삼가는게 좋고, 응용프로그램은 4~6만번대로 포트바인딩 시키는 게 좋다.

위 그림을 보면 짐작할 수 있는데,
어떤 목적지에 도착하기 위해서는 IP주소와 포트번호가 모두 필요하고, (IP주소 + 포트번호)를 소켓 주소라고 부른다.
Unix에서는 well-known 포트 번호들이 /etc/services 파일에 저장되어 있다.
이를 이용하여 Mac에서는 grep tftp /etc/services 를 입력하면, 해당 파일에서 tftp 서비스의 포트 번호를 출력한다.
tftp 69/udp
tftp 69/tcp아마 이렇게 나올 것이다.
이는 tftp 라는 이름을 가지는 서비스는 UDP 프로토콜 69번 포트, TCP 프로토콜 69번 포트를 사용한다는 것이다.
Pushing과 Pulling

Pushing과 Pulling은 모두 데이터를 전송하는 방법을 표현하는 용어다.
일반적으로 Pushing은 실시간으로 변경되는 데이터나 시스템 간 통신에 사용된다.
Pushing은 데이터를 생산자(송신자)가 소비자(수신자) 상태를 보지 않고 패킷을 밀어 넣는 것을 의미한다.
이 방식에서는 생산자가 데이터를 보내는 즉시, 수신자가 그 데이터를 받아야한다.
Pushing은 데이터를 강제로 전송하는 방식이기 때문에,
무턱대고 데이터를 꾸준히 들이밀면 수신 buffer Overflow가 발생할 수 있다.
이를 막기 위해 '흐름 제어(flow control)'를 필요로 한다. 흐름 제어는 다음 글에서 알아본다.
Pulling은 소비자(수신자)가 데이터를 요청하고 생산자(송신자)가 그 데이터를 보내주는 방식이다.
수신자가 데이터를 요청하지 않으면, 데이터를 전달하지 않는다.
Pulling은 일반적으로 파일 전송이나, 웹 페이지 request에 사용된다.
네트워크 장애와 Connectionless Service
크게 4가지의 네트워크 장애가 발생할 수 있다.
1. bit 오류 : 0이 되어야 하는 bit가 1이 되거나 그러한 오류들.
2. Lost Packet : 패킷 분실
3. Duplicated Packet : 패킷 중복
4. Out-of-Order : 패킷 순서가 뒤바뀌는 에러
TCP에서는 이런 에러가 발생하지 않도록 에러 컨트롤을 해준다. ( UDP는 그런 거 없다. )
앞서 UDP의 경우 비연결 서비스(Connectionless Serivce)라고 언급했다.
따라서 UDP의 경우, 패킷의 순서가 뒤죽박죽 되어 수신될 수 있다.
아 그러면 UDP는 안 좋아 보이는데, 왜 쓰는가? 하면 신뢰성 서비스를 제공하지 않는 대신에 속도가 빠르다.
그래서 Real-TIme-Service(일단 패킷을 받는 게 중요한 실시간 멀티미디어 서비스들)들이 UDP를 썼다.
일반적으로 DNS request는 UDP로 보내곤 한다. DNS request가 작은 데이터이기 때문에 가능하다.
반면 TCP처럼 연결 지향 서비스는 ACK를 보내서 각종 에러를 control 하거나,
응용 프로세스에 패킷의 순서를 맞춰서 데이터를 올려 보내는 서비스를 제공하기 때문에 비교적 느리다.
다만, error가 발생하면 안 되는 전자메일 서비스, 인터넷 뱅킹 등에서는 무조건 TCP를 사용한다.
IP 자체는 연결 지향적인 프로토콜이 아니므로, Connectionless로 작동한다.
즉, 패킷 전송 시에 연결 설정 과정이 필요 없이, 각 패킷이 독립적으로 전송되고 도착한다.
Connection-Oriented 이런 거는 상위 계층인 TCP에서 담당하는 것이다.
'Computer Network' 카테고리의 다른 글
| [컴퓨터 네트워크] 14-1. TCP 개요 (0) | 2023.04.26 |
|---|---|
| [컴퓨터 네트워크] 13. UDP 간단 정리 (0) | 2023.04.22 |
| [컴퓨터 네트워크] 11. Segmentation vs Fragmentation (0) | 2023.04.20 |
| [컴퓨터 네트워크] 10. DHCP 개념과 과정 (0) | 2023.04.18 |
| [컴퓨터 네트워크] 9. 인터넷, WWW, HTTP, HTTPS, SMTP, IMAP, POP (0) | 2023.04.18 |


