
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Docker
- dockerfile
- 데이터 엔지니어링
- HADOOP
- sql
- redshift
- S3
- 데이터 파이프라인
- 자료구조
- linux
- 파이썬
- http
- 컴퓨터네트워크
- PYTHON
- airflow
- 정리
- 데브코스
- 종류
- 데이터엔지니어링
- 가상환경
- Django
- Go
- 데이터 웨어하우스
- airflow.cfg
- TCP
- 데이터베이스
- TIL
- AWS
- 운영체제
- 컴퓨터 네트워크
Archives
- Today
- Total
홍카나의 공부방
[데이터베이스] B+Tree, 인덱스의 종류 본문
B+ 트리

- MySQL은 B+트리로 인덱스가 구현되어 있다.
- B+ 트리는 인덱스 세트와 순차 세트라는 2가지 세트를 만든다.
- 인덱스 세트는 내부 노드로, 리프에 있는 키들에 대한 경로만 제공한다.
- 모든 키 값은 순차 세트(리프 노드)에 있다.
- 인덱스 세트는 직접 탐색을 지원하며, 순차 세트는 순차 탐색을 지원한다.
- B+ 트리는 B트리와 다르게 Best도 없고 Worst도 없다. 탐색은 무조건 O(log N)이다.
- B+ 트리의 루트 및 내부 노드 구조에는 레코드에 대한 포인터 값이 제외되어 있다.
- 반대로 리프 노드는 루트 및 내부 노드와 다르게 서브트리에 대한 포인터가 없다. 대신 레코드에 대한 포인터 값이 있고, 다음 리프노드에 대한 포인터가 존재한다.
- 순차 세트의 모든 리프 노드는 링크드 리스트 형태로 연결되어 있으므로, 순차 탐색이 B-Tree에 비해서 효율적이다.
- 정리하자면 직접 탐색은 B-Tree의 연산이 우세, 순차 탐색은 B+ Tree의 연산이 우세하다.
B+ 트리의 삽입과 삭제
- 삽입은 B-Tree와 대부분 유사하다.
- 단, 리프 노드의 overflow가 발생할 때는 두 개의 노드로 분할하고 키 값들을 절반씩 분배하여 저장하는데, 분할된 왼쪽 노드에서 가장 큰 키 값의 복사본을 부모 노드로 올려서 저장한다.
- 이렇게 해서 부모 노드와 분할 노드 모두 키 값이 존재하도록 만든다. ( 인덱스 세트, 순차 세트에 모두 키 값이 있는 게 B+Tree의 특징이다. )
- 삭제는 리프에서만 삭제한다. 어차피 인덱스 세트에 있는 키 값은 경로 탐색용으로만 사용하기 때문에 굳이 안지워도 된다.
- 단, 리프 노드에서 언더 플로우가 발생했을 경우에는 1) 형제 노드의 키 개수를 확인한 뒤, 재분배가 가능하면 재분배 2) 재분배가 불가능하면 합병한다. 합병의 경우 인덱스 키 값도 삭제된다. 필요가 없으니깐.
인덱스의 종류 - 클러스터 인덱스
- 클러스터링이란, 쉽게 말해서 특성이 유사한 것끼리 모아두는 것을 의미한다.
- 클러스터 인덱스는 레코드들의 물리적인 저장 순서가 인덱스 순서와 동일하게 되도록 구성한 인덱스다.
- 그리고 인덱스의 리프 노드가 곧 데이터 레코드로, 쉽게 말하면 인덱스 파일과 데이터 파일이 같은 파일로 존재한다.
- 데이터들을 물리적으로 같은 트랙, 같은 실린더에 배치한다면 탐구 시간(seek time)이 감소시켜 속도를 높일 수 있다.
- 사전과 유사하다. 영한 사전을 찾아보면 비슷한 영단어는 비슷한 위치에 있다. 그리고 영단어를 찾아보면 데이터도 같이 있다. 이게 바로 클러스터 인덱스의 예시다.
- 클러스터 인덱스는 보조 인덱스보다 검색 속도가 더 빠르다. 동일하거나 인접한 키 값을 가진 레코드들을 물리적으로도 인접하게 저장하기 때문이다.
- 단, 데이터의 입력/수정/삭제는 보조 인덱스보다는 느리다. 동일하게 옆에 붙여야 하기 때문에 '이동'을 할 가능성이 높기 때문.
- 클러스터 인덱스는 여러 개 만들 수 없다. 만약 학번이라는 속성으로 클러스터 인덱스를 B+Tree로 만들었는데, 이름으로 또 물리적인 인덱스는 만들 수 있을까? 없다. 데이터를 물리적으로 또 어떻게 저장하라는 이야기인가.
- 일반적으로 클러스터 인덱스는 PK(기본키)로 만든다.
- 테이블 생성 시 기본키에 대해 클러스터 인덱스를 자동으로 생성한다.
- 기본 키를 지정하지 않으면 처음 나오는 UNIQUE 속성에 대하여 인덱스를 생성한다. ( 그런데 이런 경우 잘 없다. )
인덱스의 종류 - 보조 인덱스(secondary index)
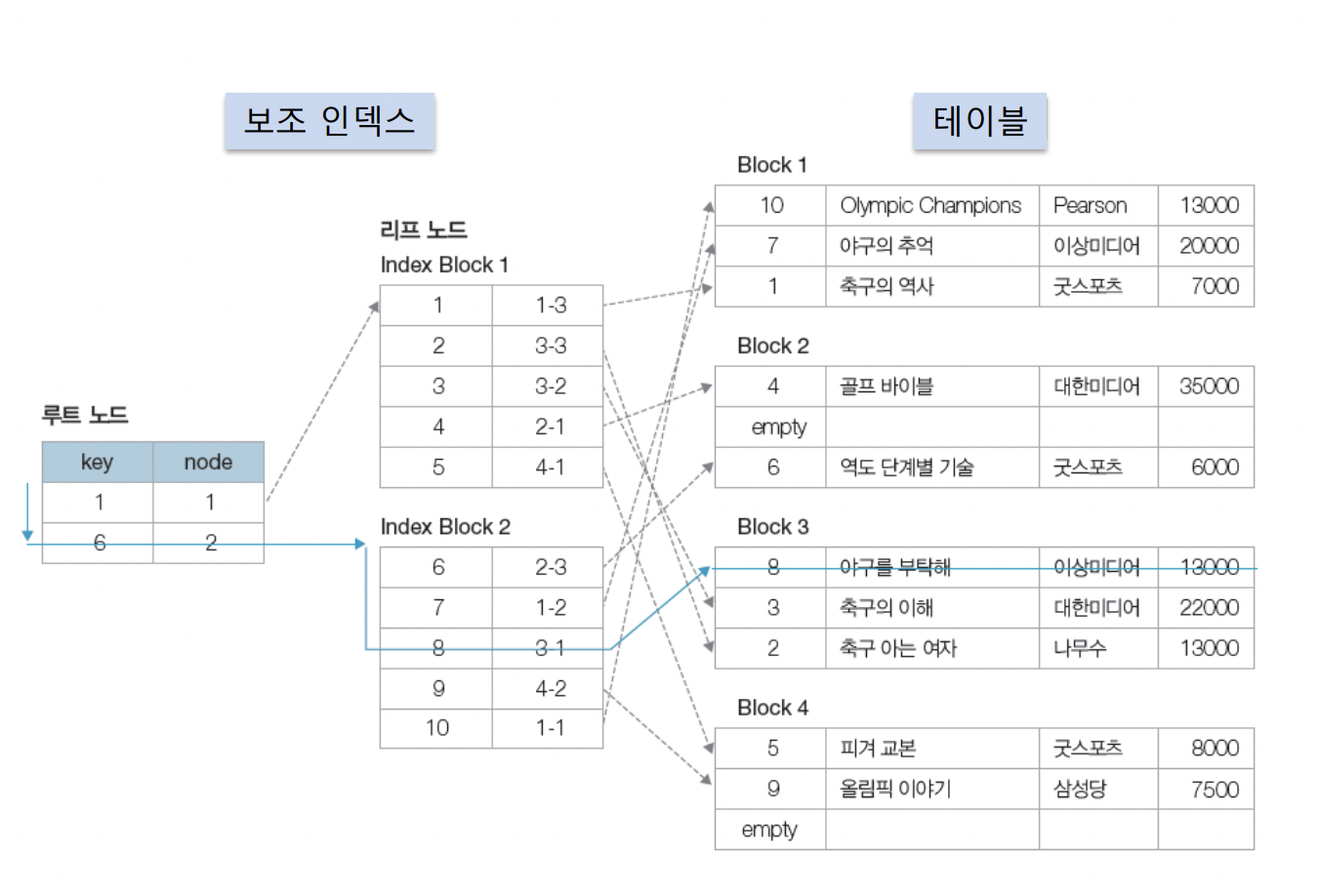
- 클러스터 인덱스가 아닌 모든 인덱스를 가리킨다.
- 보조 인덱스는 책 뒤의 <찾아보기>랑 비슷하다. 보조 인덱스는 원하는 만큼 여러 개를 만들 수 있다.
- 보조 인덱스는 인덱스 파일만 수정하면 되기 때문에, 클러스터 인덱스보다 입력, 수정, 삭제가 더 빠를 수 있다.
- 단, 검색 속도는 더 느리다. 인덱스 파일 찾은 다음에 주소로 가서 데이터 파일을 읽어내야 하니까 더 느릴 수밖에 없다. 디스크 연산이 더 많이 진행되기 때문이다.
- 보조 인덱스와 클러스터 인덱스를 동시에 사용할 수도 있는데, 이 때는 1) 보조 인덱스를 검색하여 Primary key 속성의 값을 찾고, 2) 클러스터 인덱스에서 해당 레코드를 검색한다. 실제로 MySQL을 사용할 때는 이런 방법(Select와 where절을 이용하여)으로 값을 찾아가기도 한다.
MySQL 인덱스 생성 예시
- 인덱스 생성은 다음과 같다.
-- 테이블 생성시
create table 테이블이름 (
...
index 인덱스이름 (속성1, 속성2, ...), -- ix_student_no 등 ix를 접두사로 붙여서 만들어주자.
...
);
-- 추후 인덱스 생성시
create index 인덱스이름
on 테이블이름 (속성1, 속성2, ...);
인덱스 사용 장점과 단점
- pros) 인덱스된 속성에 대한 질의를 처리할 때 대상이 되는 데이터 양이 줄어들어 처리 속도가 힙 파일보다 빠르다.
- cons) 클러스터 인덱스에서 insert가 자주 사용되는 경우 부하가 크다.
- 인덱스는 모든 속성에 대해 만들어 놓지 말고 Where, JOIN절에 자주 사용되는 속성에 만들어두자.
반응형
'Data Engineering > Database' 카테고리의 다른 글
| [데이터베이스] 삭제 : DELETE vs DROP vs TRUNCATE (0) | 2023.05.20 |
|---|---|
| [데이터베이스] 저장 구조 - 해싱 방법, 저장 구조의 비교 (0) | 2023.05.18 |
| [데이터베이스] 저장 구조 - 순차 방법(힙), B-Tree (0) | 2023.05.18 |
| [데이터베이스] 하드 디스크의 구조 (0) | 2023.05.14 |
| [데이터베이스] 릴레이션, 스키마, 관계형 데이터베이스 개요와 SQL (0) | 2023.05.08 |
'Data Engineering/Database' Related Articles
more



