
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터엔지니어링
- TIL
- 가상환경
- airflow
- 운영체제
- AWS
- 데이터 엔지니어링
- redshift
- dockerfile
- 데이터베이스
- 자료구조
- http
- linux
- 컴퓨터네트워크
- 정리
- 컴퓨터 네트워크
- 데이터 웨어하우스
- 종류
- Go
- airflow.cfg
- Docker
- TCP
- HADOOP
- 데브코스
- 파이썬
- Django
- 데이터 파이프라인
- S3
- sql
- PYTHON
- Today
- Total
홍카나의 공부방
[강화학습] 4강 - Model-Free Prediction 본문
모델을 모를 때 Prediction 문제를 푸는 방법을 알아본다.
Model은 강화 학습에서 환경의 모델(model of enviornment)의 줄임말로, 에이전트의 액션에 대해 환경이 어떻게 응답할지 예측하기 위해 사용하는 모든 것을 가리킴. 에이전트의 액션에 대하여 환경이 어떻게 반응할지 알 수 있다면, 에이전트 입장에서는 여러가지 Planning을 세워볼 수 있기에 모델을 아는 것이 큰 도움이 된다.
Prediction은 Policy가 정해져있는 상태에서 Value Fuction을 찾는 문제, Control은 Optimal Policy 그리고 Optimal Value Fuction을 찾는 문제다. ( 컨트롤은 정책이 정해져있지 않다. )
Monte-Carlo Reinforcement Learning
- 몬테카를로(MC)는 직접 구하기 어려운 것을 episode들을 돌리면서 추정하는 것
- model-free 문제에서 사용 ( MDP의 transition, reward를 모를 때.. )
- 잘 모르니까 그냥 천만 번 돌려본다~ 경험으로 부터 배운다~ 라고 이해하면 쉽다.
- episode가 끝나야 return ( reward들의 cumulative sum )을 알 수 있다.
- can only apply MC to episodic MDPs( 에피소드가 끝나야 적용할 수 있음. )
Monte-Carlo Policy Evaluation
- 에피소드 별로 V_pi를 배우는 것
- value function은 return의 기댓값이다.
- return은 할인되는 보상의 총합이다. ( 2강 때 다 배운 내용이다. )
First-Visit Monte-Carlo Policy Evaluation
- 에피소드에서 특정 state를 처음 방문했을 때만 Counter를 증가시킨다.
- Every-Visit은 counter를 state를 방문할 때마다 Counter를 증가시킨다.
- V(s) = S(s) / N(s), 즉 리턴의 합/방문의 횟수기 때문에 First 방법과 Every 방법은 값이 처음에는 다를 수 있다.
Temporal-Difference Learning
- TD 방법은 경험으로부터 직접적으로 배우는것
- MDP에 대한 지식이 필요 없음.
- TD는 incomplete한 에피소드로부터도 배울 수 있음.
- 한 순간의 차이로 V(S_t)를 업데이트해서 TD Learning이라고 한다.
- 추측치로 추측치를 업데이트하는 Bootstrapping과 거의 일치함.

Pros and Cons of MC vs. TD
- TD는 최종 결과가 나오기 전까지 학습할 수 있다.
- every step마다 실시간으로 배울 수 있다.
- 반면 MC는 에피소드 하나가 완전히 끝나서 return을 알기 전까지에는 기다려야한다.
- TD는 final outcome이 없어도 학습할 수 있다.
- 반면 MC는 완벽한 결과로부터만 배울 수 있다.
- TD는 non-terminating 환경에서도 작동 가능하다.
- MC는 terminating 환경에서만 작동 가능하다.
Bias/Variance Trade-Off (편향/분산 트레이드 오프)
- 전지전능한 Oracle이 True TD Target만을 알려준다면, unbiased estimate다.
- 근데 biased estimate니까 샘플링을 몇 백만번 한다해도 TD target이 V_pi가 된다는 확신이 없는 것이다.
- Bias 관점에서는, TD가 굉장히 안좋아 보이는데 Variance 관점에서 본다면... TD가 오히려 분산이 적어서 유리


Batch MC and TD, AB Example
- 한정된 에피소드만 가지고 있을 때, MC와 TD가 같은 곳에 수렴할까? 혹은 수렴은 할까?
- 경험들만으로 V(A), V(B)를 평가하는 AB Example이 나옴.
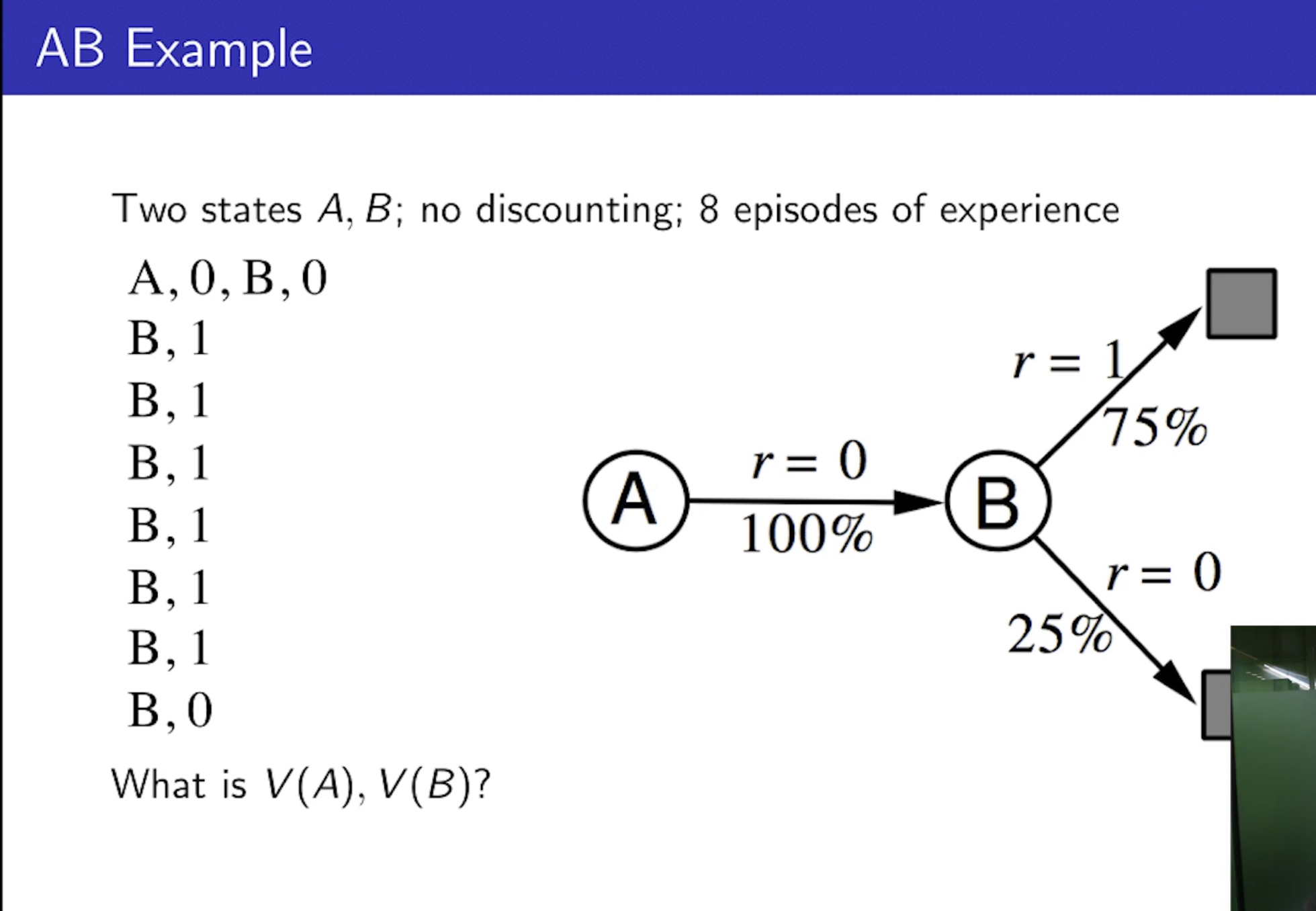
- TD는 마르코프 특성을 사용한다.
- MC는 마르코프 특성을 사용하지 않고, Mean-Square Error를 minimize하는 방법이다.
Bootstrapping and Sampling
- 추측치로 추측치를 업데이트하는 부트스트래핑.
- 샘플링은 하나의 샘플을 가지고 업데이트를 하는 것.
- MC는 부트스트래핑을 하지 않음 ( 끝까지 가보니까 )
- DP와 TD는 부트스트래핑을 함.
- MC와 TD는 step의 단계만 다를 뿐 샘플링을하고, DP는 가능한 모든 action을 다 해보니까 샘플링을 하지 않음.
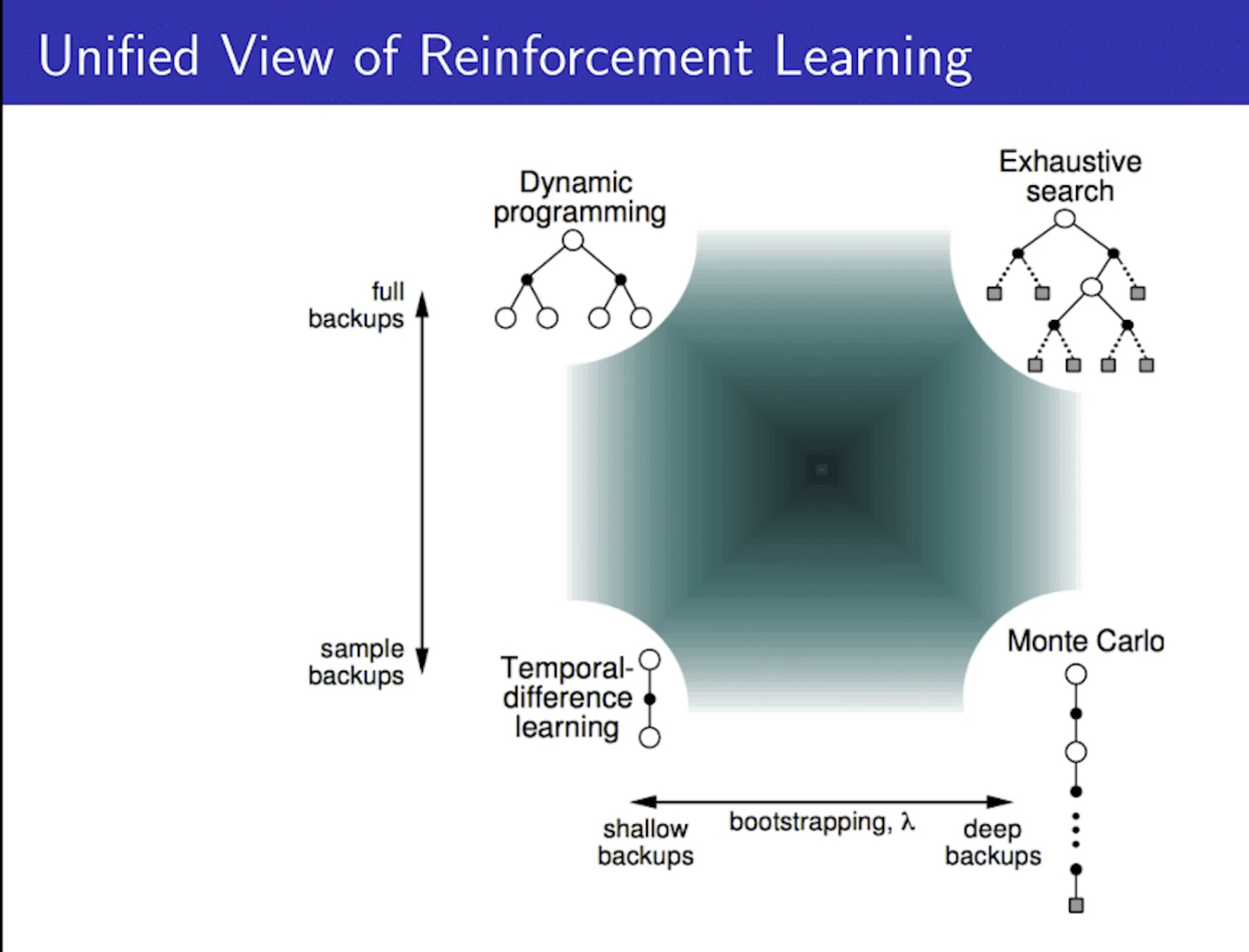
- Deep backup ( 부트스트래핑을 하지 않음 )
- Shallow backup ( 부트스트래핑을 진행해서 추정을 함 )
- full backup ( 샘플링을 하지 않음 )
- sample backup ( 샘플링을 진행 )
n-Step Prediction (Return)
- step을 몇 번을 진행하느냐에 따라 TD와 MC를 둘다 사용할 수 있음.
- 아래 슬라이드를 보고 직관적으로 이해할 수 있으면, 강의를 어느정도 이해한 것!
- TD와 MC사이에 sweet ratio가 있다!

TD-lambda
- 중요하다고 언급이 되었기에.. 이것만 따로 정리해야할 것 같아서
https://daeson.tistory.com/334
RL (강화학습) 기초 - 8. TD lamda
1 step TD의 step을 증가시켜 나가면서 n 까지 보게 되면 n step TD로 일반화를 할 수 있습니다. 만약 step이 무한대에 가깝게 되면 MC와 동일하게 될 것입니다.2 step TD 에서의 업데이트 방식은 첫번째 보
daeson.tistory.com
'AI > Reinforcement Learning' 카테고리의 다른 글
| hey chatGPT, 강화학습을 배우려면 어떻게 해야해? (0) | 2022.12.06 |
|---|---|
| [강화학습] 3강 학습 노트 - Planning by DP (2) | 2022.12.04 |
| [강화학습] 2강 학습 노트 - Markov Decision Process (0) | 2022.11.28 |
| [강화학습] 기초 이론 1강 학습노트 (0) | 2022.11.26 |



